



Now a days this topic is very popular KGO - Knowledge Graph Optimization. How to Do it? Let's Say if you find information about Sachin Tendulkar Google reach the query related to Sachin Tendulkar in its database and show a panel on the right side of the SERP with images and important information about him.
We are thinking always this question where is this information coming from? The information we get is a mixture between information that other user found useful and informative post on knowledge graph. If there is a problem, then we have the option of feedback button, submit the problem and information will be modified correctly On Google and Wikipedia.

'
 What is the Impact of Knowledge Graph on SEO ?
What is the Impact of Knowledge Graph on SEO ?As we know Knowledge Graph is based on information data. From this Webmasters have trouble in terms of ranking and traffic as well.
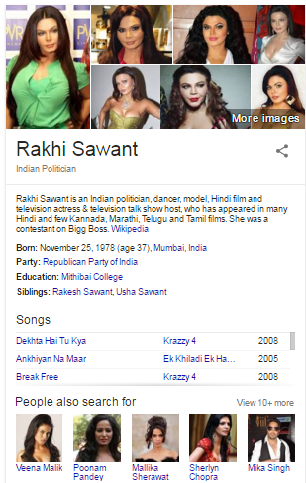
Let's take example the search query entered Rakhi Sawant on right hand side all the information about Rakhi sawant is there so user would go through to this information rather then click on Rakhi Sawant officially website. We can also see the search query competitor here you can see in the result showing Poonam Pandey and Mallika Sherawat..






 Submit your Email Address to Get Free latest Articles Directly to your Inbox
Submit your Email Address to Get Free latest Articles Directly to your Inbox